ASCII Lab在NLPCC2025大模型生成文本检测共享任务中获得第一名
发布时间:2025年05月15日
NLPCC 2025(第14届自然语言处理与中文计算国际会议)是中国计算机学会自然语言处理专业委员会(CCF-NLP)主办的年度国际会议,专注于自然语言处理和中文计算领域。 今年,NLPCC 2025 延续以往会议的传统,举办了多个自然语言处理与中文计算领域的共享任务(Shared Tasks)。今年的共享任务涵盖经典问题与新兴挑战,其中任务一就是大模型生成文本检测。
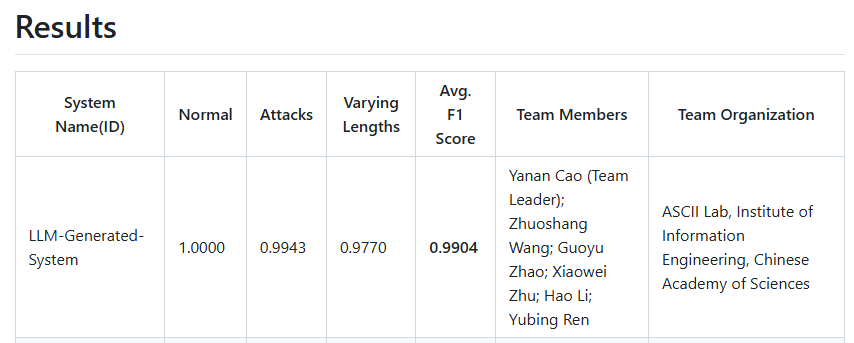
信息工程研究所ASCII Lab实验室参加了本次NLPCC 2025大模型生成文本检测共享任务。经过团队成员一个月的开发与调试,我们设计的检测系统在性能测试中超越了来自北航、北理、北师等高校及企业,最终获得了第一名的成绩,证明了团队在中文机生文本检测领域的研究实力和技术水平。相关系统可用于学术研究与工程应用。
任务介绍
随着大型语言模型的迅速发展,其生成文本的质量正逐步接近人工撰写的水平。然而,这些模型也带来了诸多挑战,例如可能生成虚假信息、有害内容,或被用于不当用途。因此,如何有效区分大型语言模型生成的文本与人工撰写的文本,已成为一个重要且紧迫的问题。尽管在检测大型语言模型生成文本方面已有显著进展,但相关研究主要集中在英语领域。相比之下,针对中文的研究仍显得相对不足。本次共享任务旨在弥补这一空白,通过开发更强大的检测算法来识别大型语言模型生成的中文文本,从而推动中文领域相关研究的深入发展。
参赛者需要基于提供的原始训练数据,设计并构建检测算法,用以区分大型语言模型生成的文本和人工撰写的文本。在评估阶段,所有提交的检测器将在模拟真实场景的测试条件下(尤其是分布外数据的情况下)进行严格测试,以全面评估其实际效果和鲁棒性。为确保公平性和结果可追溯性,参赛者禁止使用外部数据源或基于外部知识生成新的数据样本。此外,所有训练数据和相关脚本需提交进行审查,以保证任务的公平性、透明性和可复现性。